Db2
IBM Db2 is a relational database known for its high performance, scalability, and reliability in managing structured data. TapData supports using Db2 as both a source and target database, helping you quickly build data pipelines. This guide will walk you through connecting a Db2 data source in TapData.
Supported Versions and Architectures
| Category | Description |
|---|---|
| Version | Db2 9.7~11.x, with extensive validation and support for Db2 11.x Supports various platforms, including Linux, UNIX, Windows, AIX, and AS400 |
| Architecture | No limitations |
Supported Data Types
| Category | Data Types |
|---|---|
| String and Text | VARCHAR, CHARACTER, CLOB, LONG VARCHAR |
| Numeric | INTEGER, DECIMAL, BIGINT, SMALLINT, DOUBLE, REAL |
| Date and Time | TIMESTAMP, DATE, TIME |
| Boolean | BOOLEAN |
| Binary Large Object | BLOB |
| XML | XML |
SQL Operations for Sync
DML: INSERT, UPDATE, DELETE
tipWhen using Db2 as a target, TapData supports converting insert conflicts into update operations (similar to the UPSERT function).
DDL: ADD COLUMN, CHANGE COLUMN, DROP COLUMN, RENAME COLUMN
Limitations
- When performing incremental data synchronization with Db2 as the source, executing a DDL operation on the Db2 database requires running the following stored procedure immediately afterward to prevent potential synchronization failures:
CALL SYSPROC.ADMIN_CMD('REORG TABLE <schema>.<table>'); - In scenarios where the ReadLog size in Db2 is very large, incremental synchronization based on a specified time may encounter slow LRI lookup initially, potentially leading to a longer time to start incremental synchronization.
- Due to variable-length fields in the DB2 database, DML operations may trigger space expansion, resulting in discrepancies between the expected and actual operation types in task monitoring or logs (e.g., insert and delete actions appearing within an update event). Although the log may not match expectations, data accuracy remains unaffected.
- Deploying a raw log service to parse Db2 incremental data changes requires configuring the service with the same national language code as the Db2 database.
# UTF-8 Language Code
db2set db2codepage=1208
# GBK Language Code
db2set db2codepage=1386
# Country Code
db2set db2country=86
Considerations
When capturing incremental data changes, periodic calls to the Db2 ReadLog API may introduce load on the database and consume network bandwidth and disk I/O resources.
Preparation
Before connecting to a Db2 database, you need to complete account authorization and other preparatory steps. This guide provides examples assuming the Db2 database is deployed on a Linux platform.
As a Source Database
Execute the following commands in sequence to create a user for data replication/transformation tasks. On Linux, log in and execute the following commands to create a Db2 database user and set a password:
# Replace username with your desired username
sudo useradd username
sudo passwd usernameGrant permissions to the newly created account.
Log in to Db2 as a user with DBA privileges.
Execute the following commands to grant object management and data read/write permissions to a specific Schema. You can customize the permissions further based on your business needs. For more details, refer to GRANT TABLE.
- Full Data Synchronization
- Incremental Data Synchronization
-- Replace username and schema_name with the actual username and schema name
GRANT ON SCHEMA schema_name TO USER username;-- Switch to the root container
-- Replace username with the actual username
GRANT DBADM TO username;tipSince incremental extraction relies on Db2's ReadLog API, system admin or database admin privileges are required.
To perform incremental data synchronization, contact the TapData team to obtain and deploy the raw log service.
tipTo simplify the process, this service will automatically execute
ALTER TABLE <schema>.<table> DATA CAPTURE CHANGES;after it starts, enabling table-level data change capture.
As a Target Database
Execute the following commands in sequence to create a user for data replication/transformation tasks. On Linux, log in and execute the following commands to create a Db2 database user and set a password:
# Replace username with your desired username
sudo useradd username
sudo passwd usernameGrant permissions to the newly created account.
Log in to Db2 as a user with DBA privileges.
Execute the following commands to grant the user object management and data read/write permissions for the specified schema.
-- Replace schema_name and username with the actual schema name and username
GRANT CREATEIN, ALTERIN, DROPIN ON SCHEMA schema_name TO USER username;tipYou can further customize the permissions based on your business needs. For more details, refer to GRANT TABLE.
Connect to Db2
In the left navigation bar, click Connections.
On the right side of the page, click Create.
In the dialog that appears, search for and select Db2.
On the page that appears, fill in the Db2 connection details as described below.
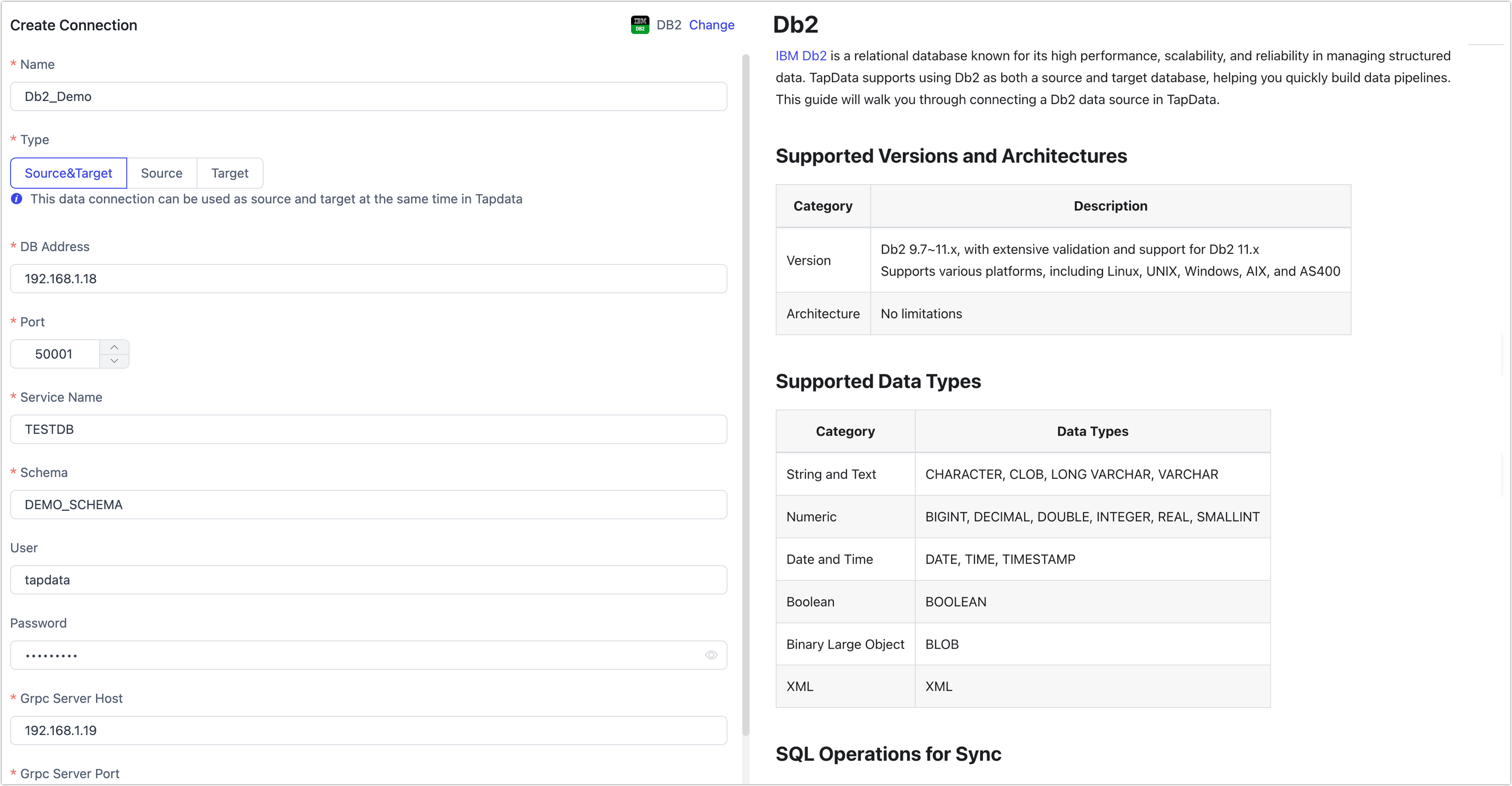
Connection Settings
- Name: Enter a unique name with business significance.
- Type: Specify whether Db2 is used as a source or target.
- DB Address: Enter the database connection address.
- Port: The service port for the database, default is 50001.
- Service Name: Enter the database name.
- Schema: Schema name, one connection per Schema. For multiple Schemas, create multiple data connections.
- Additional Connection String Parameters: Additional connection parameters, default is empty.
- User and Password: Enter the database username and password.
- Grpc Server Host, Grpc Server Port: Contact the TapData Team for raw log collection components to capture Db2 incremental data, default service port is 50051.
Advanced Settings
- Time Zone: Default is UTC (0). If changed to another timezone, it will impact the synchronization time, particularly for fields without timezone information, such as TIMESTAMP and TIME types. However, DATE types will remain unaffected.
- CDC Log Caching: Extract the incremental logs from the source database. This allows multiple tasks to share the incremental log extraction process from the same source, reducing the load on the source database. When enabled, you also need to select a storage location for the incremental log information.
- Include Tables: By default, all tables are included. You can choose to customize and specify the tables to include, separated by commas.
- Exclude Tables: When enabled, you can specify tables to exclude, separated by commas.
- Agent Settings: The default is automatic assignment by the platform. You can also manually specify an Agent.
- Model load time: If there are less than 10,000 models in the data source, their schema will be updated every hour. But if the number of models exceeds 10,000, the refresh will take place daily at the time you have specified.
- Enable Heartbeat Table: This switch is supported when the connection type is set as the Source&Target or Source. TapData Cloud will generate a table named tapdata_heartbeat_table in the source database, which is used to monitor the source database connection and task health.tip
After referencing and starting the data replication/development task, the heartbeat task will be activated. At this point, you can click View heartbeat task to monitor the task.
Click Test. If the test passes, click Save.
tipIf the connection test fails, follow the prompts on the page to troubleshoot and resolve the issue.