Features
Deliver trusted, real-time data across your systems with a unified, low-latency pipeline. This page outlines the core capabilities that make TapData a powerful live data platform.
Data Ingestion: Capture at the Source
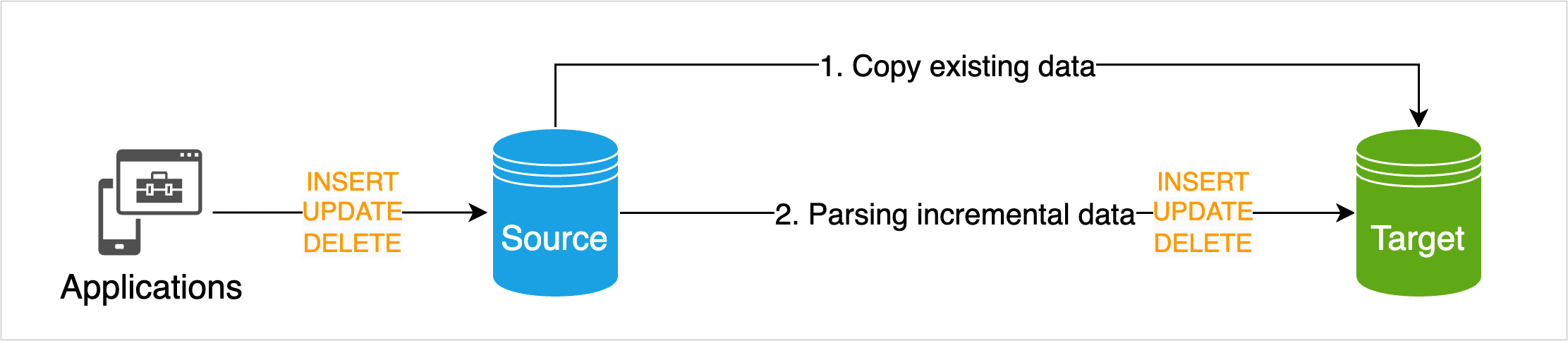
TapData supports both real-time and historical data ingestion, ensuring a complete and continuously updated view of your business data.
- Change Data Capture (CDC) Log-based CDC (e.g., MySQL binlog, PostgreSQL WAL) and trigger-based sync methods ensure sub-second latency and zero data loss with automatic retries.
- Broad Connector Ecosystem 100+ prebuilt connectors covering relational databases (Oracle, PostgreSQL, Sybase), SaaS platforms (Salesforce, Shopify), cloud services (S3, BigQuery), and legacy systems (Mainframe, FTP).
- Hybrid Pipeline Support Combine historical backfill with ongoing streaming sync in a single unified pipeline—no need to separate batch and real-time workflows.
Transformation: Prepare and Shape Data in Real Time
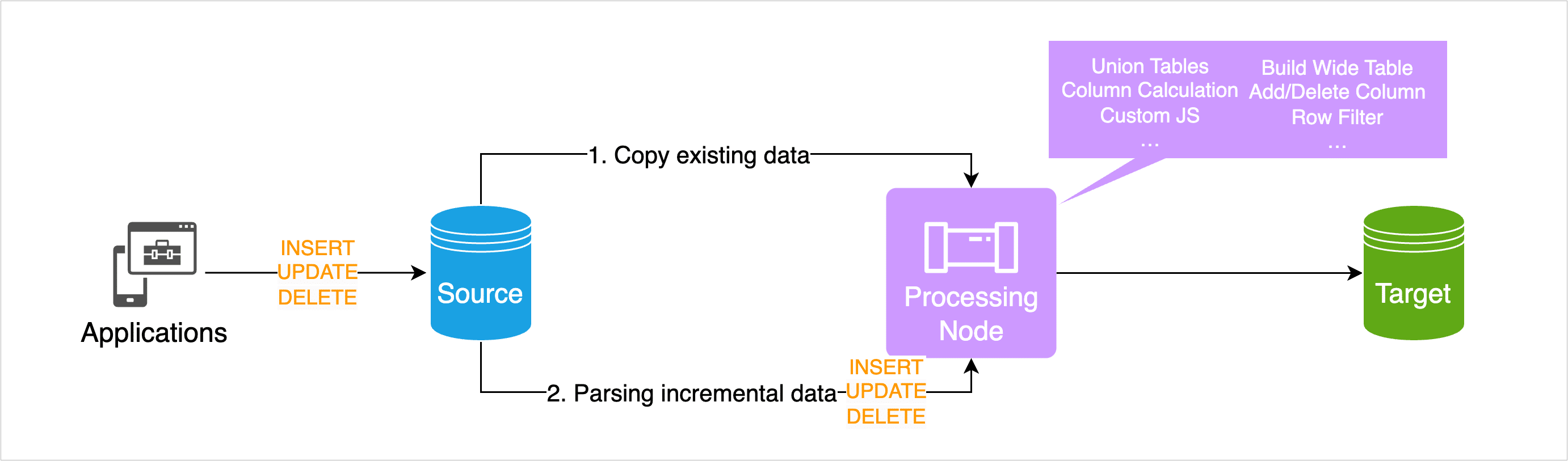
Transform your data on the fly with a zero-code interface or flexible custom logic.
- Visual Pipeline Builder
Drag-and-drop operators like
filter,join,aggregate,maskfor rapid flow creation. Power users can inject JavaScript for advanced logic. - Incremental Materialized Views (IMV) Maintain fresh, pre-computed results using CDC—no full-table recalculations. Ideal for building analytics-ready views with millisecond latency.
- Built-in Data Quality Apply schema validation and anomaly detection (e.g., null spike, value drift). Pipelines can auto-pause on quality failures to prevent bad data propagation.
Data Delivery: Serve Real-Time Data Anywhere
Distribute trusted, real-time data to downstream systems, APIs, and apps—no ETL required.
- Multi-Protocol Outputs Automatically expose your datasets as REST/GraphQL APIs, publish to Kafka, or sync directly to data warehouses like Snowflake or Delta Lake.
- Virtual Data Products
Publish curated business views (e.g.,
user_profile,finance.revenue) with access controls, lineage, and usage monitoring—ideal for MDM, analytics, or API-based consumption.
Operational Control: Build with Confidence
Enterprise-grade governance and deployment options let you manage pipelines at scale with full observability.
- Governance & Security Track full lineage from source to consumer. Protect sensitive fields with masking and hashing (GDPR/CCPA ready). RBAC and Kubernetes-native deployment supported.
- Pipeline Monitoring Built-in dashboards show lag, throughput, and error metrics. Proactive alerts via Slack, email, or webhook.
- Flexible Deployment Run on-premises, in the cloud, or across hybrid environments. Cross-cloud sync supported (e.g., RDS → Synapse).
Developer Experience: Built for Extensibility
Whether you're building pipelines or extending the platform, TapData offers tools for full lifecycle automation.
- API-First Control Manage pipelines via declarative configs (YAML/JSON), CLI, or Terraform.
- Custom Extensions Build your own connectors in Java/JS. Extend pipeline logic with plugin architecture.
AI Agent Integration: Connect LLMs to Live Data (Preview)
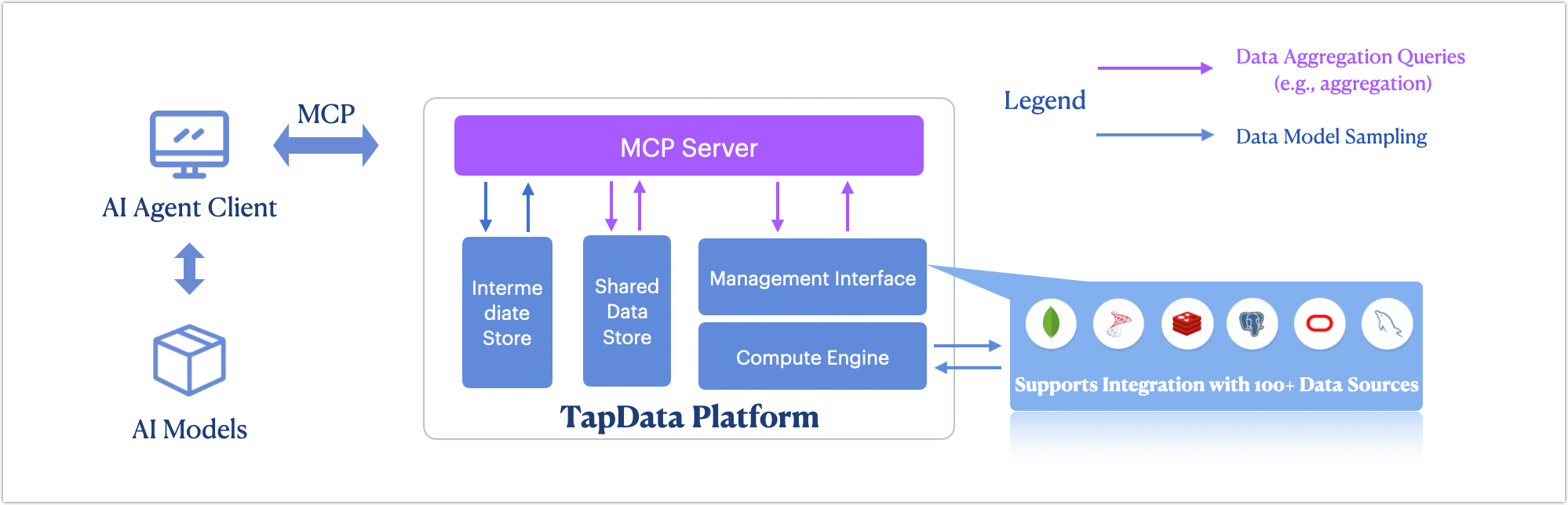
Empower AI models and agents with real-time business context through standardized protocols.
- LLM & Agent Integration Connect popular AI tools like Cursor, Claude, and custom agents to your live data through Model Context Protocol (MCP).
- Real-Time Context Delivery MCP provides structured, real-time business data to AI models, enhancing inference accuracy and reducing hallucinations.
- Enterprise-Ready Security Field-level masking, role-based permissions, and controlled access ensure AI models get only authorized, fresh data during inference.