GaussDB (DWS)
GaussDB (DWS) is a fully managed, enterprise-grade cloud data warehouse service offering zero-maintenance, online scaling, and efficient multi-source data loading capabilities. It is compatible with the PostgreSQL ecosystem. TapData supports using GaussDB (DWS) as both a source and a target, enabling you to quickly build data pipelines. This guide explains how to connect GaussDB (DWS) in the TapData platform.
Supported Versions and Architectures
- Version: GaussDB (DWS) 8.1.3
- Architecture: Standalone or clustered
Supported Data Types
| Category | Data Types |
|---|---|
| Strings | VARCHAR, VARCHAR2, TEXT, CHAR, NVARCHAR2 |
| Numbers | INTEGER, BIGINT, SMALLINT, NUMERIC, DECIMAL, REAL, DOUBLE PRECISION |
| Boolean | BOOLEAN |
| Date/Time | TIMESTAMP, TIMESTAMP WITH TIME ZONE, TIMESTAMP WITHOUT TIME ZONE, TIME, TIME WITH TIME ZONE, TIME WITHOUT TIME ZONE, INTERVAL |
| Binary | BYTEA |
| Bit Strings | BIT, BIT VARYING |
| Network | CIDR, INET, MACADDR |
| Geometry | POINT, LSEG, BOX, PATH, POLYGON, CIRCLE |
| Other | UUID, XML, JSON, JSONB |
SQL Operations for Sync
- DML: INSERT, UPDATE, DELETE
- DDL (supported only as a target): ADD COLUMN, CHANGE COLUMN, DROP COLUMN, RENAME COLUMN
- As a source, incremental data synchronization is achieved via field polling, and DDL operations are not supported. See Change Data Capture (CDC) for more details.
- As a target, advanced configuration options allow you to set DML conflict handling strategies. For example, you can choose to update or discard on insert conflicts and choose to insert or log errors on update failures.
Limitations
- When using GaussDB (DWS) in a cluster architecture as the source for incremental synchronization, high availability for CDC is not yet supported. If a primary node switchover occurs, incremental sync may experience errors or interruptions.
- When synchronizing tables without primary keys to GaussDB (DWS), you must disable unique index constraints for update conditions to avoid table creation failures.
- By default, GaussDB (DWS) uses primary keys as distribution columns. Manually specified distribution columns must be included in the primary key, unique index, or update condition, or table creation will fail.
- If the source performs unsupported operations, such as modifying distribution columns, GaussDB (DWS) will convert the update to a delete followed by insert. This requires the source update event to include complete
Afterdata fields. For example, Oracle sources must enable the complete logging of all fields feature.
What is the distribution column?
In GaussDB (DWS), distribution columns determine how data is distributed across nodes in a distributed table, impacting query performance. For more details, see Best Practices for Choosing Distribution Columns.
Prerequisites
Log in to the GaussDB (DWS) database and execute the following commands to create a user for synchronization or transformation tasks.
CREATE USER username WITH PASSWORD 'password';- username: The user name.
- password: The password.
Grant the required permissions to the newly created user.
- As Source
- As Target
-- Switch to the database where permissions will be granted
\c database_name
-- Grant USAGE permission and table read access within the Schema
GRANT USAGE ON SCHEMA schema_name TO username;
GRANT SELECT ON ALL TABLES IN SCHEMA schema_name TO username;-- Switch to the database where permissions will be granted
\c database_name;
-- Grant USAGE and CREATE permissions for the target Schema
GRANT CREATE,USAGE ON SCHEMA schemaname TO username;
-- Grant read and write permissions on tables in the target Schema
GRANT SELECT,INSERT,UPDATE,DELETE,TRUNCATE ON ALL TABLES IN SCHEMA schemaname TO username;
-- Grant USAGE permission for the target Schema
GRANT USAGE ON SCHEMA schema_name TO username;
-- Due to GaussDB (DWS) limitations, TapData grants the following permissions for tables without primary keys to ensure updates and deletions work correctly
-- ALTER TABLE schema_name.table_name REPLICA IDENTITY FULL;- database_name: The database name.
- schema_name: The schema name.
- username: The user name.
Connect to GaussDB(DWS)
Click Connections in the left navigation bar.
Click Create on the top-right of the page.
Search for and select GaussDB (DWS) in the pop-up dialog.
Fill in the connection details as follows:
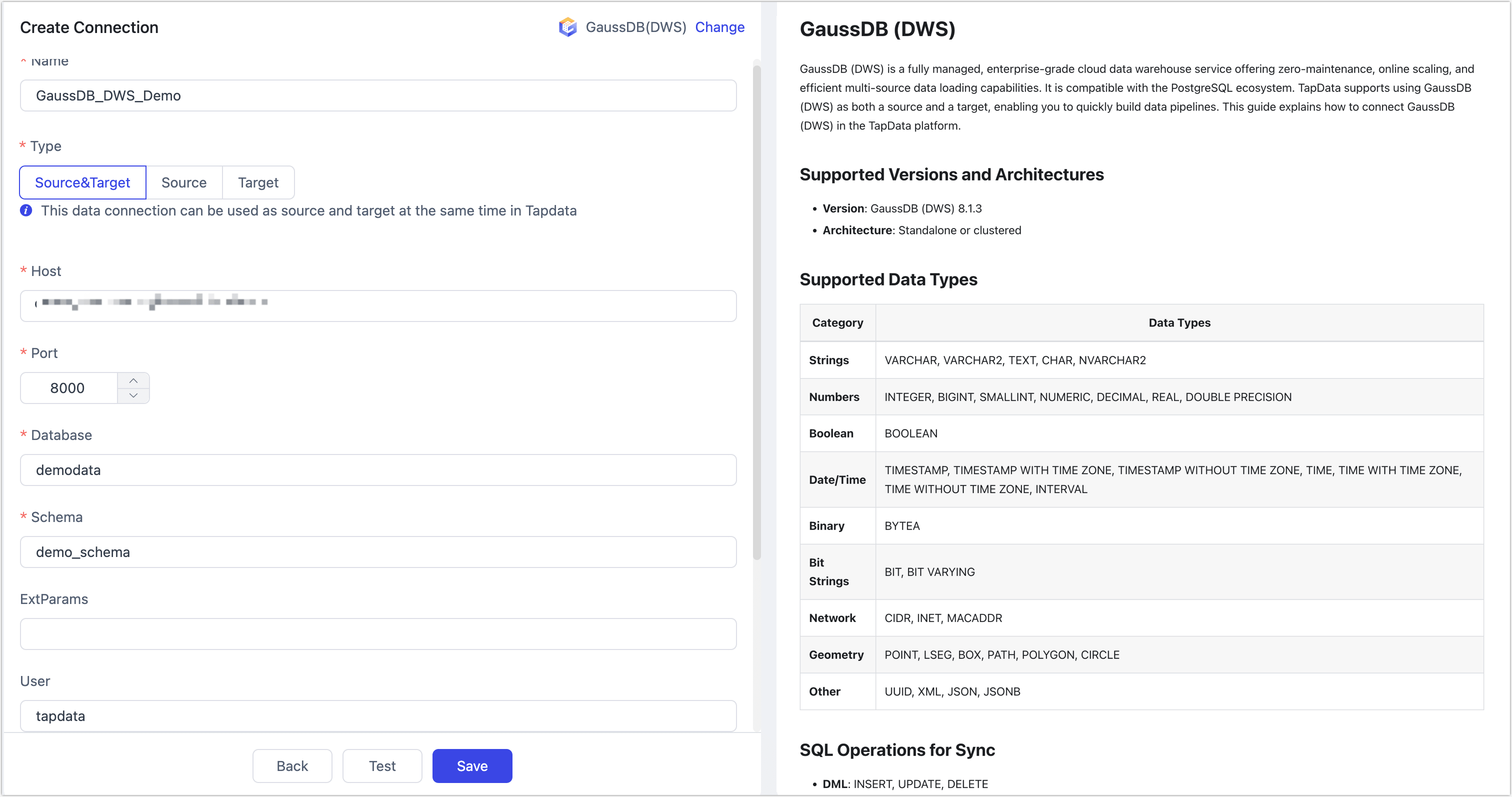
- Connection Settings
- Name: Enter a unique and meaningful name.
- Connection Type: Specify whether GaussDB (DWS) is used as a source or a target.
- Host: The database connection address. See Obtaining the Connection Address of a GaussDB(DWS) Cluster.
- Port: The HTTP API port of the database, which defaults to 8000.
- Database: The database name. One connection corresponds to one database. Create separate connections for multiple databases.
- Schema: The schema name.
- ExtParams: Optional connection parameters.
- User/Password: The database username and password.
- Time Zone: Default is UTC (0). Non-time-zoned fields (e.g., TIMESTAMP) are affected if changed. Time-zoned fields (e.g., TIMESTAMP WITH TIME ZONE) and DATE are unaffected.
- Advanced Settings
- Contain table: The default option is All, which includes all tables. Alternatively, you can select Custom and manually specify the desired tables by separating their names with commas (,).
- Exclude tables: Once the switch is enabled, you have the option to specify tables to be excluded. You can do this by listing the table names separated by commas (,) in case there are multiple tables to be excluded.
- Agent settings: Defaults to Platform automatic allocation, you can also manually specify an Agent.
- Model Load Time: If fewer than 10,000 schemas, refresh every hour. Otherwise, refresh daily at a specified time.
- Connection Settings
Click Test at the bottom of the page. If the test is successful, click Save.
If the test fails, follow the error prompts to resolve the issue.
Node Advanced Features
When configuring GaussDB (DWS) as a source or target node in a synchronization or transformation task, TapData provides advanced features to optimize performance and meet complex business requirements:
- Ignore NotNull: Enabled by default to prevent empty strings from being stored as
NULLand conflicting with NOT NULL constraints. Disable if empty strings do not need handling. - Replace Empty Strings: Resolves primary key issues with empty strings by replacing them with a specified value.
- Distribution Columns: Supports
distribute by hashfor even distribution. Distribution fields must be part of the primary key or update conditions. - Enable File Input: Boosts performance by using file stream imports. Not supported for binary types or conflict scenarios.